Quando si parla di apprendimento si pensa subito alle reti neurali o ai chip che simulano il comportamento dei neuroni. Ma in realtà utilizzare reti neurali piuttosto che normali CPU e normali tecniche di programmazione, provoca solo differenze riguardo alle velocità di risposta e ai consumi di energia.
Una qualunque matrice, o array di dati, può memorizzare esperienze esattamente come fanno le reti neurali. Andando al limite anche una Macchina di Turing potrebbe eseguire gli stessi algoritmi e ottenere gli stessi risultati, ma sarebbe lentissima.
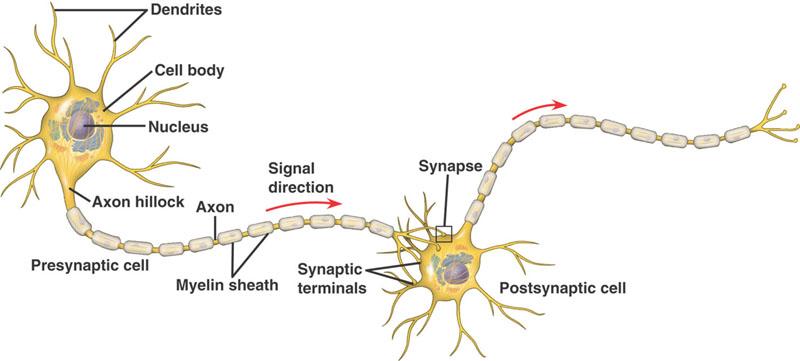
Quando ero piccolo (32 anni circa) pensavo ingenuamente di costruire computer con componenti elettronici disposti in celle strutturate come i neuroni. Secondo questi principi ognuno dei neuroni simulati contiene una cella di memoria che rappresenta il livello di attivazione (chiamato “peso”) e eventualmente una seconda cella che rappresenta il guadagno e determina il livello di uscita. E infine ogni neurone simulato deve contenere moltiplicatori analogici o digitali e collegamenti verso un certo numero di altri neuroni cui inviare il segnale di uscita.
Oggi alcuni gruppi di ricerca stanno producendo chip neuromorfici basati su questi stessi ingenui principi e naturalmente questi sistemi funzionano, anche una Macchina di Turing funzionerebbe. Ma per costruire qdroidi serve una efficienza notevolmente maggiore, un salto quantico, un diverso modo di utilizzare le risorse elettroniche disponibili.
Utilizzare elettroni e silicio per simulare il funzionamento
di esseri basati su neurotrasmettitori chimici e carbonio
non è la soluzione più efficiente.
L’evoluzione degli esseri viventi basati sul carbonio aveva a disposizione molecole, messaggi chimici e DNA e con questi mattoni la soluzione migliore trovata sono stati i neuroni. Ma i componenti attuali basati sul silicio sono miliardi di volte più veloci rispetto ai segnali chimici per cui dobbiamo tenere conto di queste possibilità e utilizzarle in modo efficiente.
In futuro si utilizzeranno tecniche che ora nemmeno immaginiamo, ma ora abbiamo i componenti in silicio e il modo più efficiente di usarli non è costringerli a simulare quello che non sono. Bisogna solo aggiungere il non determinismo attivato dalla casualità e strutturarli in modo adeguato.
Per ora “aggiungere il non determinismo” è solo una bella frase e non abbiamo idea di come si potrà fare, ma se è possibile ci riusciremo. Qualche esperienza la abbiamo già con la programmazione non deterministica.
Confidiamo nell’aiuto del professore Anselmi per una analisi di fattibilità. Quello che ci serve è il suo intuito su questi argomenti. Si tratta di fare un calcolo statistico approssimativo che ci dica se vale la pena di fare esperimenti in questo senso o se le combinazioni casuali da provare e quindi il tempo richiesto per ottenere qualche risultato, siano talmente grandi da sconsigliare a priori ogni tentativo basato sulla programmazione classica.
Calcolo matriciale con le schede video
Le CPU dei computer attuali agiscono in modo sequenziale e sono troppo lente per memorizzare e trattare in parallelo grandi quantità di dati. Ma fortunatamente ci sono le schede video che possono operare su enormi matrici e compiere le stesse operazioni su un gran numero di elementi ad altissima velocità e simultaneamente. Vedere la documentazione del Toolkit Cuda di NVIDIA.
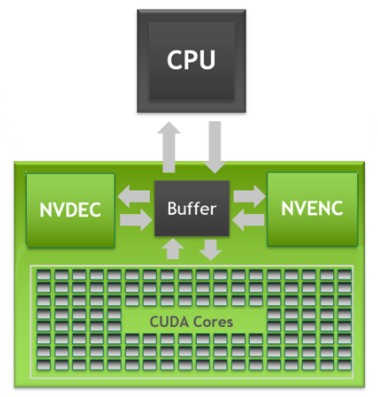
Alcune di queste schede hanno 10752 processori (CUDA Cores) ed ogni core contiene due processori che possono fare anche operazioni in floating point a 32 bit.

Con le tecnologie attuali probabilmente questa è l’unica possibilità che abbiamo di ottenere qualche risultato utile partendo dalle casualità quantistiche.
L’idea di utilizzare le capacità di calcolo parallelo delle schede video per il calcolo neurale è già ampiamente utilizzata, vedere ad esempio questa pagina. Però le implementazioni attuali cercano ingenuamente di simulare il funzionamento dei neuroni.
Le implementazioni attuali sono inefficienti e troppo lente per i qdroidi,
come già spiegato nel capitolo precedente di questa pagina.